S3 Durability and Availability
Amazon simple storage service Lifecycle offers more than one class of storage for your objects. The class you choose will depend on how critical it is that the data survives no matter what (durability), how quickly you might need to retrieve it (availability), and how much money you have to spend.
1. Durability
S3 measures durability as a percentage. For instance, the 99.999999999 percent durability guarantee for most S3 classes and Amazon Glacier is as follows:
“. . . corresponds to an average annual expected loss of 0.000000001% of objects.
For example, if you store 10,000,000 objects with Amazon S3, you can on average expect to incur a loss of a single object once every 10,000 years.”
Source: https://aws.amazon.com/s3/faqs
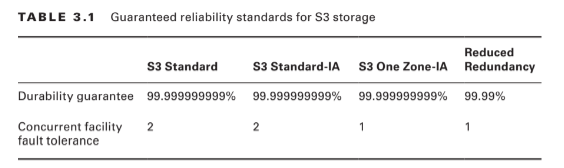
In other words, realistically, there’s pretty much no way that you can possibly lose data stored on one of the standard S3/Glacier platforms because of infrastructure failure. However, it would be irresponsible to rely on your S3 buckets as the only copies of important data. After all, there’s a real chance that a misconfiguration, account lockout, or unanticipated external attack could permanently block access to your data. And, as crazy as it might sound right now, it’s not unthinkable to suggest that AWS could one day go out of business. Kodak and Blockbuster Video once dominated their industries, right? The high durability rates delivered by S3 are largely because they automatically replicate your data across at least three availability zones. That means that even if an entire AWS facility was suddenly wiped off the map, copies of your data would be restored from a different zone. There are, however, two storage classes that aren’t quite so resilient. Amazon S3 One Zone-Infrequent Access (S3 One Zone-IA), as the name suggests, stores data in only a single availability zone. Reduced Redundancy Storage (RRS) is rated at only 99.99 percent durability (because it’s replicated across fewer servers than other classes). You can balance increased/decreased durability against other features like availability and cost to get the balance that’s right for you. All S3 durability levels are shown in Table 3.1.
2. Availability
Object availability is also measured as a percentage, this time though, it’s the percentage you can expect a given object to be instantly available on request through the course of a full year. The Amazon S3 Standard class, for example, guarantees that your data will be ready whenever you need it (meaning: it will be available) for 99.99% of the year. That means there will be less than nine hours each year of down time. If you feel down-time has exceeded that limit within a single year, you can apply for a service credit. Amazon’s durability guarantee, by contrast, is designed to provide 99.999999999% data protection. This means there’s practically no chance your data will be lost, even if you might sometimes not have instance access to it. Table 3.2 illustrates the availability guarantees for all S3 classes.

3. Eventually Consistent Data
It’s important to bear in mind that S3 replicates data across multiple locations. As a result, there might be brief delays while updates to existing objects propagate across the system. Uploading a new version of a file or, alternatively, deleting an old file altogether can result in one site reflecting the new state with another still unaware of any changes. To ensure that there’s never a conflict between versions of a single object—which could lead to serious data and application corruption—you should treat your data according to an Eventually Consistent standard. That is, you should expect a delay (usually just two seconds or less) and design your operations accordingly. Because there isn’t the risk of corruption, S3 provides read-after-write consistency for the creation (PUT) of new objects.
Also Read : Amazon Simple Storage Service
Related Product : AWS Certified Solutions Architect | Associate
4. S3 Object Lifecycle
Many of the S3 workloads you’ll launch will probably involve backup archives. But the thing about backup archives is that, when properly designed, they’re usually followed regularly by more backup archives. Maintaining some previous archive versions is critical, but you’ll also want to retire and delete older versions to keep a lid on your storage costs. S3 lets you automate all this with its versioning and lifecycle features.
5. Versioning
Within many file system environments, saving a file using the same name and location as a pre-existing file will overwrite the original object. That ensures you’ll always have the most recent version available to you, but you will lose access to older versions—including versions that were overwritten by mistake. By default, objects on S3 work the same way. But if you enable versioning at the bucket level, then older overwritten copies of an object will be saved and remain accessible indefinitely. This solves the problem of accidentally losing old data, but it replaces it with the potential for archive bloat. Here’s where lifecycle management can help.
6. Lifecycle Management
You can configure lifecycle rules for a bucket that will automatically transition an object’s storage class after a set number of days. You might, for instance, have new objects remain in the S3 Standard class for their first 30 days after which they’re moved to the cheaper One Zone IA for another 30 days. If regulatory compliance requires that you maintain older versions, your fi les could then be moved to the low-cost, long-term storage service Glacier for 365 more days before being permanently deleted.
Accessing S3 Objects
If you didn’t think you’d ever need your data, you wouldn’t go to the trouble of saving it to S3. So, you’ll need to understand how to access your S3-hosted objects and, just as important, how to restrict access to only those requests that match your business and security needs.
7. Access Control
Out of the box, new S3 buckets and objects will be fully accessible to your account but to no other AWS accounts or external visitors. You can strategically open up access at the bucket and object levels using access control list (ACL) rules, finer-grained S3 bucket policies, or Identity and Access Management (IAM) policies. There is more than a little overlap between those three approaches. In fact, ACLs are really leftovers from before AWS created IAM. As a rule, Amazon recommends applying S3 bucket policies or IAM policies instead of ACLs. S3 bucket policies—which are formatted as JSON text and attached to your S3 bucket— will make sense for cases where you want to control access to a single S3 bucket for multiple external accounts and users. On the other hand, IAM policies—because they exist at the account level within IAM—will probably make sense when you’re trying to control the way individual users and roles access multiple resources, including S3. The following code is an example of an S3 bucket policy that allows both the root user and the user Steve from the specified AWS account to access the S3 MyBucket bucket and its contents.
8. Presigned URLs
If you want to provide temporary access to an object that’s otherwise private, you can generate a presigned URL. The URL will be usable for a specified period of time, after which it will become invalid. You can build presigned URL generation into your code to provide object access pro grammatically. The following AWS CLI command will return a URL that includes the required authentication string. The authentication will become invalid after 10 minutes (600 seconds). The default expiration value is 3,600 seconds (one hour).
9. Static Website Hosting
S3 buckets can be used to host the HTML files for entire static websites. A website is static when the system services used to render web pages and scripts are all client rather than server-based. This architecture permits simple and lean HTML code that’s designed to be executed by the client browser. S3, because it’s such an inexpensive yet reliable platform, is an excellent hosting environment for such sites. When an S3 bucket is configured for static hosting, traffic directed at the bucket’s URL can be automatically made to load a specified root document, usually named index.html. Users can click links within HTML pages to be sent to the target page or media resource. Error handling and redirects can also be incorporated into the profile.
If you want requests for a DNS domain name (like mysite.com) routed to your static site, you can use Amazon Route 53 to associate your bucket’s endpoint with any registered name. This will work only if your domain name is also the name of the S3 bucket. You’ll learn more about domain name records in Chapter 8, “The Domain Name System (DNS) and Network Routing: Amazon Route 53 and Amazon CloudFront.” You can also get a free SSL/TLS certificate to encrypt your site by requesting a certificate from Amazon Certificate Manager (ACM) and importing it into a CloudFront distribution that specifies your S3 bucket as its origin.
Questions related to this topic
- How is data stored in Amazon s3 for high durability?
- Which storage class can be used for long term archive storage?
- Where is s3 data stored?
- Can you store objects smaller than 128 kb in Amazon s3’s standard IA storage class?
This Blog Article is posted by
Infosavvy, 2nd Floor, Sai Niketan, Chandavalkar Road Opp. Gora Gandhi Hotel, Above Jumbo King, beside Speakwell Institute, Borivali West, Mumbai, Maharashtra 400092
Contact us – www.info-savvy.com

